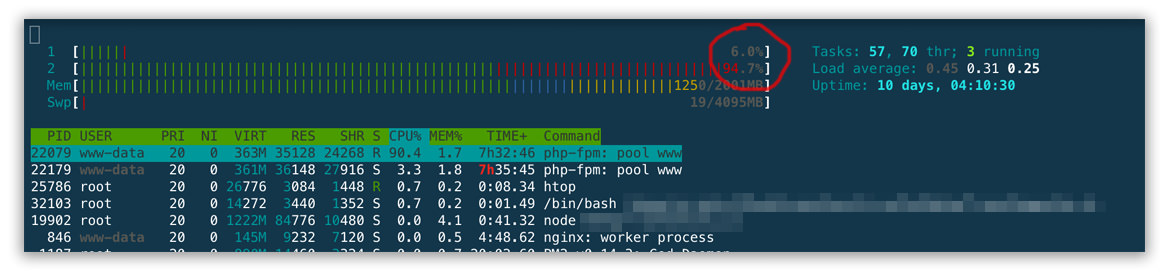
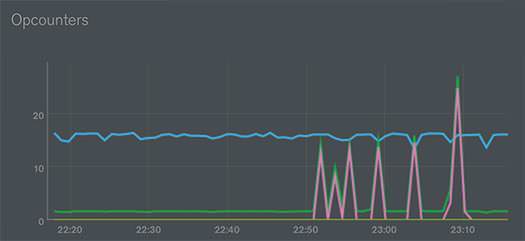
Here is how you can install MongoDB 3.4.x on Ubuntu 16.04 and secure it. I use the Studio 3T software form Studio 3T.
Before you install MongoDB ensure you have secured your server and installed it and installed an SSL certificate. Click the links here to set up a Digital Ocean, Vultr or AWS Server. Read my old guide to installing MongoDB on Ubuntu 14.04 and using Studio 3T ( https://studio3t.com/ ).
Install MongoDB 3.6
Official guide here
Add the keyserver
Update
Install the latest stable version of MongoDB
sudo apt-get install -y mongodb-org
MongoDB.conf options
FYI: Secure MongoDB: https://docs.mongodb.com/manual/security/ and Security Checklist https://docs.mongodb.com/manual/administration/security-checklist/
MongoDB Hardening Info: https://docs.mongodb.com/manual/core/security-hardening/
Start Mongodb
You should see startup activity
In a new terminal window open a MongoDB process
mongo --port 27017 --authenticationDatabase 'admin' --username username --password password
>...
>
Create a user
Create a test db
Run MongoDB at Startup
Note: I tried setting up a service but it failed so I added the following command to /etc/rc.local
Todo: Service Setup.
Ignore the following….
Create a service
I added
TIP: Bing to local 127.0.0.1 and also your external IP (if you have hardened and setup IP whitelists for the port).
Make /etc/init.d/mongod executable
Firewall
Configure your firewall (tip: whitelist your local development IP to allow your IP access etc)
Reload the firewall and show the status. Add port 27017 (or your custom port) to your TCP and UDP firewall. http://icanhazip.com/ will display your public IP.
Display the MongoDB version
Make MongoDB configuration changes
– Consider saving your database data somewhere else (mongodb.conf)
– Consider redirecting your log file (mongodb.conf)
systemLog: destination: file logAppend: true path: "/folder_to_store_mongodb_logs/mongo.log"
– Consider changing the default MongoDB port (mongodb.conf)
net: port: 27123
– Allow MongoDB to talk locally and globally if need be and optionally enable IPV6 (binding IP’s in mongodb.conf)
TIP: Ensure you bind you localhost port (127.0.0.1) AND your public IP (e.g 123.123.123.123) as you will need to bind to public IP too if you want to connect to MongoDB externally. I did not bing my eternal IP and was blocked for a few days.
If you allow external access then consider whitelisting your IP and disabling local admin login – more here (mongodb.conf)
Official configuration documentation can be found here.
At this stage, MongoDB is open to the world and if you connect to your server with no username or password you will see it is open.
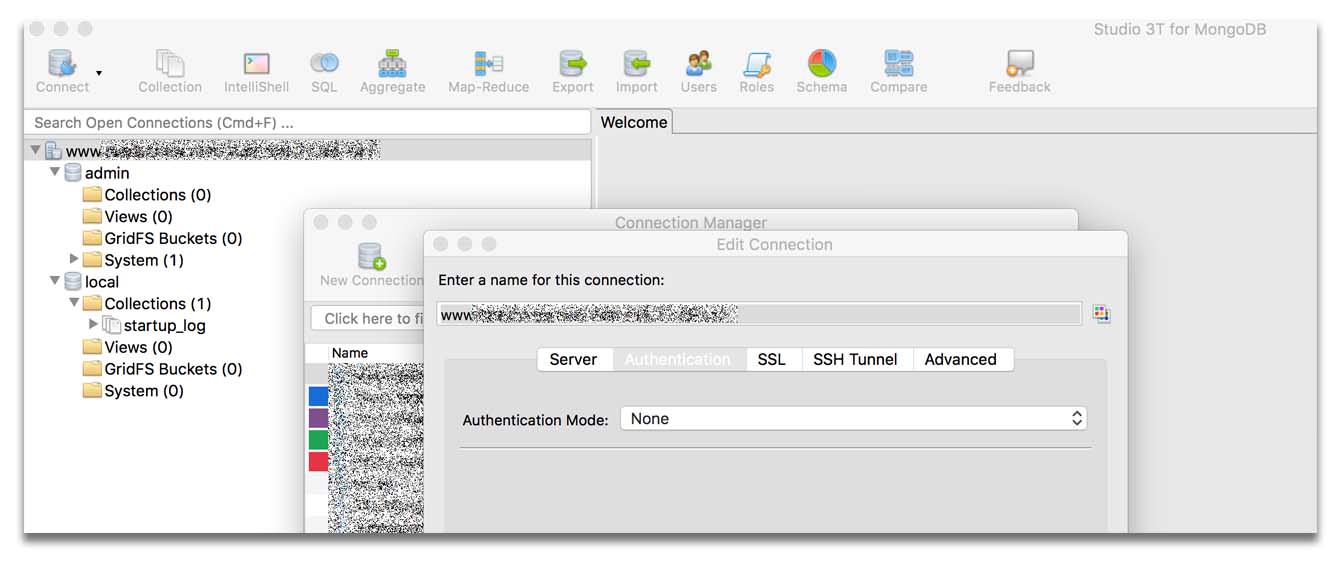 I created an admin user with Studio 3T for MongoDB in the IntelliShell.
I created an admin user with Studio 3T for MongoDB in the IntelliShell.
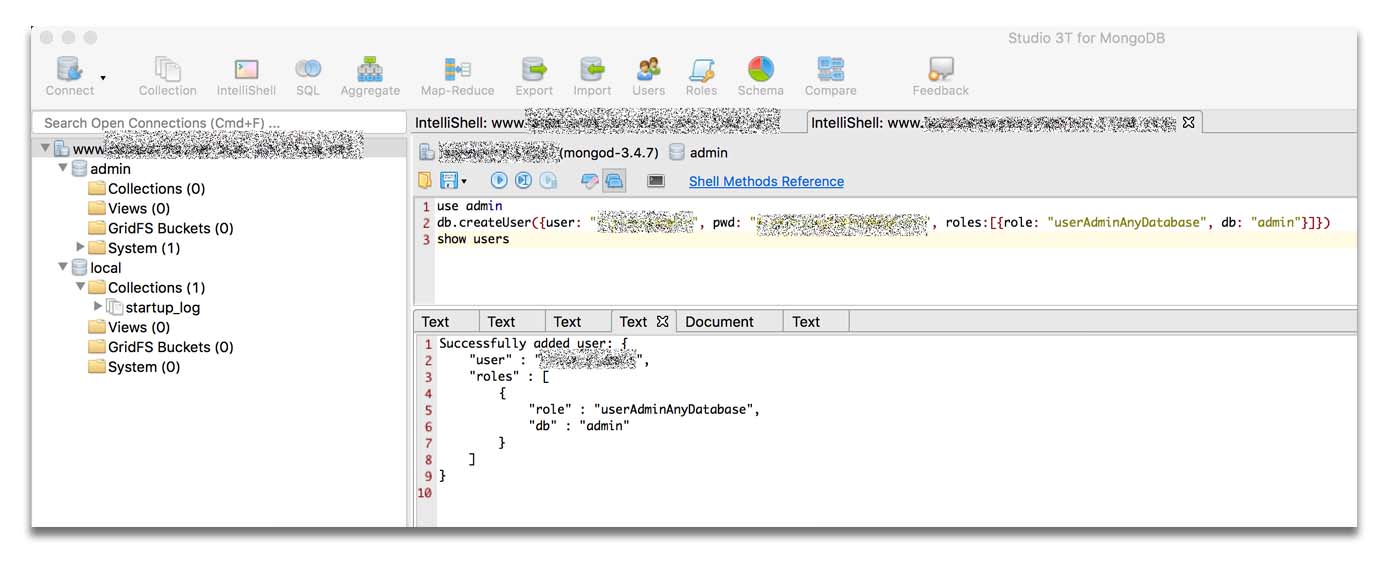 I typed the following to create a user (I added a root role after creating the screenshot above).
I typed the following to create a user (I added a root role after creating the screenshot above).
Verify that the user was created
Now you can use these credentials to log in to the database.
You can see the new credentials are working and now we need to remove anonymous and empty connections.
Add the following to mongodb.conf
Restart MongoDB
or
/usr/bin/mongod --config /etc/mongod.conf
Now when you connect to your database with no login details you will see no databases.
Show the status of MongoDB
View the last 20 lines of the MongoDB log file.
(or replace the path with your log location)
tail -n 20 /yourmongodb_logs/mongod.log
Viewing MongoDB files
MongoDB Users and Roles
More on securing MongoDB here and here.
Remove MongoDB
Remove MongoDB files
cd /mongodb_data_folder/ rm -R *.* rm -R WiredTiger rm -R journal
Remove MongoDB
I had these warnings with MongoDB 3.2
I CONTROL [initandlisten] ** WARNING: /sys/kernel/mm/transparent_hugepage/enabled is 'always'. I CONTROL [initandlisten] ** We suggest setting it to 'never'
I ran this fix.
Installing MongoDB on Ubuntu 16.04 guide here. More on SSL and MongoDB here.
todo: MongoDB Startup at reboot troubleshooting steps.
Good luck.
Donate and make this blog better
Ask a question or recommend an article
[contact-form-7 id=”30″ title=”Ask a Question”]
v1.6 Added MongoDB 3.6 install info and strat at startup
v1.5 MongoDB troubleshooting